DevOps: what it takes to be elite
UPDATE May 8, 2019: We edited the blogpost to include a Pablo's interview at "The New Stack".What does an elite software development organization look like in 2019?
We all would like to rank our practices to figure out where we are compared to other similar organizations. But it is not that easy because we normally enter into a subjective field instead of a quantitative one.
No more, thanks to "Accelerate State of DevOps Report". It contains enough data to help you find out if you are part of the elite.
Report full analysis
 |
Nicole Forsgren, Jez Humble and Gene Kim explain the report in detail in the fantastic "Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations". Humble is also the author of "The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations" which is the best book I've read on DevOps so far. Truly inspiring and easy to read. In fact, after reading this book we decided to productize our DevOps process and we created the mergebots. |
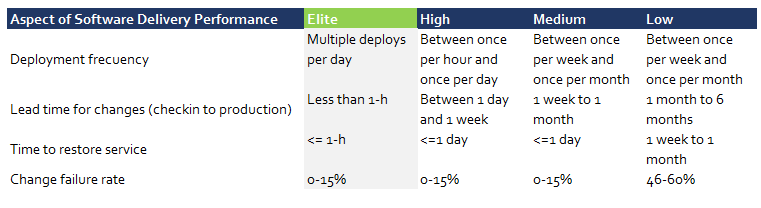
Deployment frequency
The report says:
for the primary application or service you work on, how often does your organization deploy code?
How often are you deploying to production? It seems that top performers deploy many times a day (The DevOps Handbook also explains this in detail).
The meaning of "deploy" varies wildly depending on your industry. For us at Plastic SCM, it means publishing new releases, and we do it once a day. Well, there is a caveat here. We produce potentially shippable releases at least once a day, but since we don't want to overwhelm users, we publish only once or twice a week.
The technique we use is as follows: every task/bug branch is merged to main once it is reviewed, validated and tested, and then the new potentially deployable version is marked with a build number in an attribute:

The versions actually released are labelled instead (green circle).
We achieve this (and recommend teams using Plastic to do the same) through task branches and trunk-based development. In short:
- Everything is a task in your issue tracker (both bugs and new features, refactors, anything).
- Create a branch for each task.
- Finish it in less than 2-3 days (split work accordingly to achieve it).
- Code review each task branch by another team member.
- Validate each task branch (someone does a quick test manually). This is optional depending on the nature of your project. For us, it is key.
- Test each task branch by the automated tests. Lots of unit tests, a few integration tests, even fewer GUI tests. Keep it simple and fast. Slow tests won't let you become elite.
- Merge each task branch to main if it passes its tests.
- Every new changeset in main is deployable.
Lead time for changes
The study says:
For the primary application or service you work on, what is your lead time for changes (i.e., how long does it take to go from code commit to code successfully running in production)?
Imagine the simplest possible change in your codebase. You just touch a single line. How long does it take to reach production?
This might sound simple, but this minimal change has to go through the entire pipeline. It has to be code reviewed, tested, and then deployed.
As usual in DevOps, automation is the key to becoming elite. And also, a super-fast test suite.
In our case, we are not yet in the elite because a simple change takes a minimum of 2 hours before it reaches a release. This is because our test-suite grew too large and despite intense parallelization, it still requires 2 hours.
I recently wrote a blogpost about "cycle time and lead time" and how we changed our way of working moving from Scrum to Kanban.
Time to restore service
For the primary application or service you work on, how long does it generally take to restore service when a service incident occurs (e.g., unplanned outage, service impairment)?
A pure Ops requirement. How fast are you restoring your service when something goes wrong? The goal for the elite is less than 1 hour.
I believe that for many teams who develop cloud software that this might not be such a big challenge as the previous two thanks to cloud providers putting together most of the required infrastructure. It is also out of the scope for companies developing embedded devices, most video-games (except when we talk about online games, by the way, which are now a large part of the equation) and many others.
Change failure rate
For the primary application or service you work on, what percentage of changes results either in degraded service or subsequently requires remediation (e.g., leads to service impairment, service outage, requires a hotfix, rollback, fix forward, patch)?
In short, how many new releases break the software?
I bet the biggest challenge will be to properly track the failures. For SaaS teams, it will probably be straightforward, but for more traditional teams deploying software differently, it might be more of a challenge.

If you want to know more of what our approach to DevOps is, and how Plastic can help you release faster and collaborate better, listen to Pablo's interview in the leading media outlet on cloud based and modern stack development: The New Stack.


0 comentarios: